NLP 자연어 처리를 위한 RNN 기초 (2)
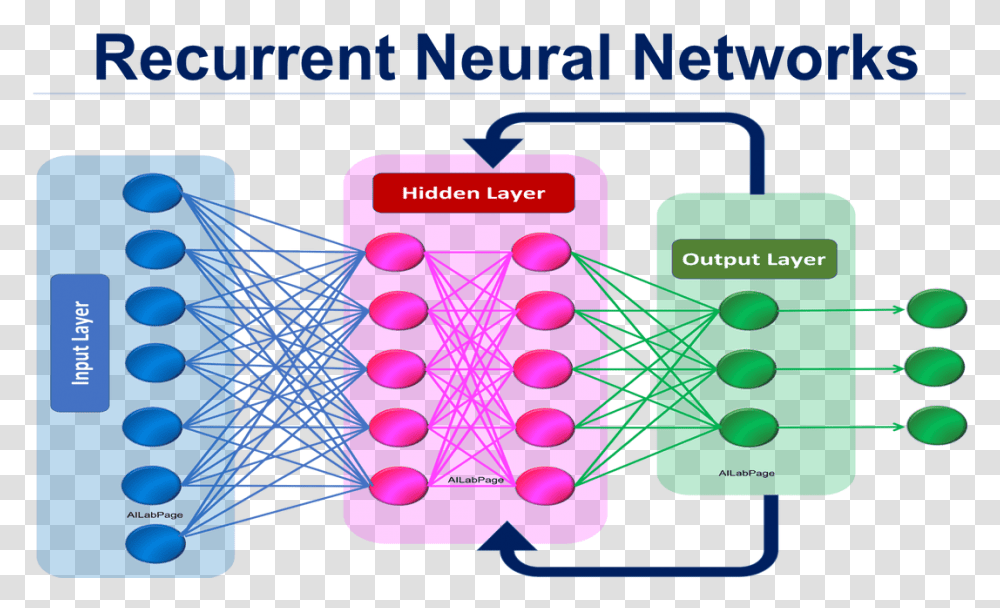
NLP 자연어 처리를 위한 딥러닝 RNN 기초 (1) RNN RNN은 Recurrent Neural Network 의 줄임말로 순환 신경망이라 불립니다. RNN 모델은 시퀀스 데이터를 효율적으로 처리하기 위해 만들어진 딥러닝 모델입니
richdad-project.tistory.com
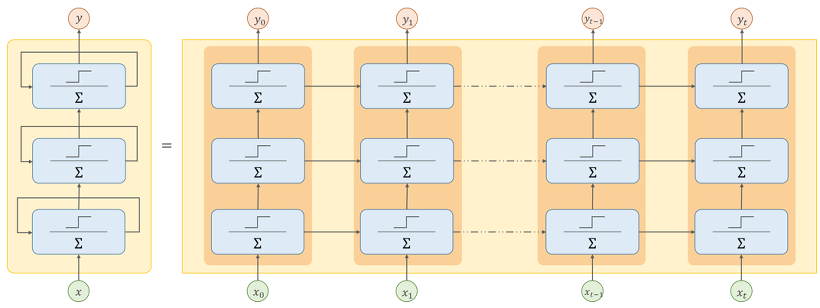
심층 RNN
지난 포스팅에서 SimpleRNN으로 모델을 구성해봤다면, 이 RNN 신경망 층을 여러개 쌓는 심층 RNN을 구현해보겠습니다. 구현은 매우 쉽습니다. SimpleRNN 층을 추가하면 됩니다.
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
tf.keras.layers.SimpleRNN(20, return_sequences=True),
tf.keras.layers.SimpleRNN(1)
])
model.compile(
optimizer = tf.keras.optimizers.Adam(),
loss = tf.keras.losses.MeanSquaredError(),
metrics = [tf.keras.metrics.MeanSquaredError()]
)
history = model.fit(
train_x,
train_y,
epochs=20,
validation_data = (val_x, val_y)
)
심층 RNN으로 구현할 경우 validation MSE 지표에서 최소값이 0.00266 정도까지 나옵니다.
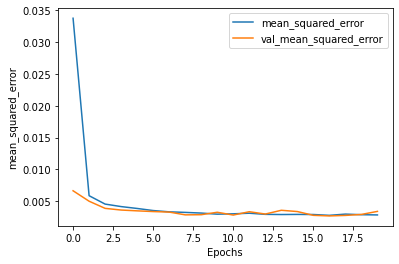

우리가 평가 기준으로 삼고 있는 MSE와 Loss의 변화 그래프입니다. 아주 예쁘게 좋은 성과를 보여주고 있습니다.
위 코드에서 RNN 층을 맨 마지막에 하나의 유닛으로 구성했습니다. 이는 결론이 하나의 값으로 귀결돼야 하기 때문입니다. 이 마지막 RNN층은 사실 타임 스텝이 넘어 갈 때 필요한 모든 정보를 하나로 축약해서 전달할 때 필요할 듯 싶습니다. 그래서 사실, 우리가 얻고 싶은 모델 결과에서 마지막 RNN층 보다는 다른 layer 쌓는 게 더 낳을 수도 있습니다. 왜냐면 RNN 층은 활성화 함수로 tanh 활성화 함수를 사용하기 때문에 다른 활성화 함수를 사용하는 layer를 넣는게 나을 수 있습니다. binary classification에서는 마지막 결론을 출력하는 층으로 Dense 층을 사용합니다.
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
# 마지막 Dense 층에 모든 정보를 전달하면서 다른 활성화 함수를 사용하기 위해
# RNN의 마지막 층은 return_sequences=True 를 지정하지 않습니다.
tf.keras.layers.SimpleRNN(20),
tf.keras.layers.Dense(1)
])
model.compile(
optimizer = tf.keras.optimizers.Adam(),
loss = tf.keras.losses.MeanSquaredError(),
metrics = [tf.keras.metrics.MeanSquaredError()]
)
history = model.fit(
train_x,
train_y,
epochs=20,
validation_data = (val_x, val_y)
)
결과는 앞에서 봤던 결과와 거의 동일하게 나옵니다. 이 모델로 훈련할 경우 빠르게 수렴하고 성능도 좋은 것으로 판단할 수 있습니다. 또한 출력층의 활성화 함수를 원하는 함수로 변동도 가능합니다.
1 이상 타임 스텝 예측
지금 까지는 바로 다음 타임 스텝의 값만을 예측해봤습니다. 그런데 10, 100, 1000 타임 스텝을 예측하고 싶을 때는 어떻게 해야할까요?
첫 번째 방법
pretrained model을 활용해서 다음 값을 예측한 후 다시 이 값을 입력값으로 넣어서 그 다음값을 예측하는 방식을 반복하면 여러 타임 스텝의 값을 예측할 수 있습니다.
새로운 데이터 예측 (심층 RNN 모델 활용)
# 새로운 데이터로 예측
new_series = generate_time_series(1, n_steps + 10)
new_x, new_y = new_series[:, :n_steps], new_series[:, n_steps:]
x = new_x
for step_ahead in range(10):
# 처음부터 하나씩 증가하면서 다음 타임 스텝을 예측 후 결과 값을 기존 값(3차원)에 추가할 수 있도록 shape 변환
recent_y_pred = model.predict(x[:, step_ahead:])[:, np.newaxis, :]
x = np.concatenate([x, recent_y_pred], axis=1)
y_prd = x[:, n_steps:]
# MSE 점수
np.mean(tf.keras.losses.mean_squared_error(new_y, y_prd))
# ==> 0.014788166
# 그래프 시각화
# 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
# 그래프 그리기
plt.plot(range(50), new_x[0].reshape(-1), 'c.-')
plt.plot(range(50,60), new_y.reshape(-1), 'mo-')
plt.plot(range(50,60), y_prd.reshape(-1), 'bx-')
plt.xlabel('t')
plt.ylabel('x(t)')
plt.legend(['학습','실제', '예측'])
plt.grid(True)
plt.show()
validation data 예측 (RNN 모델)
# 데이터 새로 다시 만들기
n_steps = 50
series = generate_time_series(10000, n_steps+10)
# train 데이터는 7000개로 구성하고 (7000, 50, 1) shape로 구성합니다.
train_x, train_y = series[:7000, :n_steps], series[:7000, -10:]
val_x, val_y = series[7000:9000, :n_steps], series[7000:9000, -10:]
test_x, test_y = series[9000: , :n_steps], series[9000: , -10:]
# 위 방식을 valistion data에 적용해보기
X = val_x
for step_ahead in range(10):
# 처음부터 하나씩 증가하면서 다음 타임 스텝을 예측 후 결과 값을 기존 값(3차원)에 추가할 수 있도록 shape 변환
recent_y_pred = model.predict(X[:, step_ahead:])[:, np.newaxis, :]
X = np.concatenate([X, recent_y_pred], axis=1)
Y_prd = X[:, n_steps:]
np.mean(tf.keras.losses.mean_squared_error(val_y, Y_prd))
# ==> 0.029840497
검증 데이터인 validation data에 적용할 경우 0.029 라는 error 값이 나옵니다. 기본 선형 모델로 적용해보면 어떻게 나올까요?
validation data 예측 (기본 선형 모델)
X = val_x
for step_ahead in range(10):
# 선형 모델인 linear_model 사용
recent_y_pred = linear_model.predict(X[:, step_ahead:])[:, np.newaxis, :]
X = np.concatenate([X, recent_y_pred], axis=1)
Y_prd = X[:, n_steps:]
np.mean(tf.keras.losses.mean_squared_error(val_y, Y_prd))
# ==> 0.06303842
0.06으로 error 값이 더 높게 나왔네요. RNN 모델이든 기본 선형 모델이든 이 방식으로는 높은 성능을 기대하기 어려울 것 같습니다. 그럼 어떻게 해결할 수 있을까요? 두 번째 방법은 다음 포스팅에서 다뤄보겠습니다.
NLP 자연어 처리를 위한 RNN 기초 (2)
NLP 자연어 처리를 위한 딥러닝 RNN 기초 (1) RNN RNN은 Recurrent Neural Network 의 줄임말로 순환 신경망이라 불립니다. RNN 모델은 시퀀스 데이터를 효율적으로 처리하기 위해 만들어진 딥러닝 모델입니
richdad-project.tistory.com
'AI > NLP' 카테고리의 다른 글
| [엘라스틱서치] 설치 및 세팅 (0) | 2023.01.07 |
|---|---|
| NLP 자연어 처리를 위한 딥러닝 - LSTM (5) (1) | 2021.12.18 |
| NLP 자연어처리를 위한 RNN 알고리즘 코드 기초 (4) - 심층 RNN (0) | 2021.12.17 |
| NLP 자연어 처리를 위한 RNN 기초 (2) (0) | 2021.12.15 |
| NLP 자연어 처리를 위한 딥러닝 RNN 기초 (1) (0) | 2021.12.14 |