NLP 자연어처리를 위한 RNN 알고리즘 코드 기초 (3) - 심층 RNN
NLP 자연어 처리를 위한 RNN 기초 (2) NLP 자연어 처리를 위한 딥러닝 RNN 기초 (1) RNN RNN은 Recurrent Neural Network 의 줄임말로 순환 신경망이라 불립니다. RNN 모델은 시퀀스 데이터를 효율적으로 처리하..
richdad-project.tistory.com
지난 포스팅에 이어 심층 RNN으로 여러개의 타임 스텝을 예측하는 문제에 대해 다뤄보겠습니다. 지난 포스팅에서는 1개의 타임 스텝의 예측값을 출력한 후 그 값을 입력값에 적용해서 그 다음 스텝을 예측하는 방식으로 살펴봤는데요. 성능이 썩 좋지 않았습니다. 그래서 이번에는 다른 방법을 소개해 보겠습니다.
한 번에 10 스텝 예측하기
두 번째 방법으로 볼 수 있는데, 한 번에 예측하고 싶은 개수 만큼 예측하는 방법입니다. 이번 포스팅 예제에서는 10개의 타임 스텝 값을 한 번에 예측해보도록 코드를 구현해 보겠습니다. 원리는 기존 RNN의 모델과 같은 시퀀스-투-벡터 형식인데, 결과값 벡터가 이전에는 1개로 구성돼 있다면 이번에는 10개로 구성되게끔 모델을 생성하면 됩니다.
# 데이터 새롭게 구성
n_steps = 50
series = generate_time_series(10000, n_steps+10)
# 출력값 벡터가 10개인 모델 구성에 맞게 데이터도 재구성
train_x, train_y = series[:7000, :n_steps], series[:7000, -10:, 0]
val_x, val_y = series[7000:9000, :n_steps], series[7000:9000, -10:, 0]
test_x, test_y = series[9000: , :n_steps], series[9000: , -10:, 0]
#######################################################################
# 모델
model = tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
tf.keras.layers.SimpleRNN(20),
# 다음 타임 스텝 10개를 한 번에 예측하기 위한 layer
tf.keras.layers.Dense(10)
])
model.compile(
optimizer = tf.keras.optimizers.Adam(),
loss = tf.keras.losses.MeanSquaredError(),
metrics = [tf.keras.metrics.MeanSquaredError()]
)
history = model.fit(
train_x,
train_y,
epochs=20,
validation_data = (val_x, val_y)
)
# MSE 확인
pred_y = model.predict(test_x)
print(np.mean(tf.keras.losses.mean_squared_error(test_y, pred_y)
# ==> 0.01045579
테스트 데이터로 평가해 본 결과 0.01로 이전보다 높은 성능을 보이고 있습니다. 하지만 여기서 더 개선할 부분이 있습니다. 현재 모델은 시퀀스-투-벡터 형식의 모델입니다. 이 말은 위에서 구성한 모든 타임 스텝의 결과를 반영하는 것이 아니라 제일 마지막 타입 스텝의 결과 값만을 반영해서 최종 출력이 나온다는 의미입니다. 그렇다면 이 모델을 시퀀스-투-시퀀스로 바꾸면 어떻게 될까요?
이 방식을 적용한다면, 마지막 타임 스텝에서 나오는 결과뿐만 아니라 모든 타임 스텝에서 출력되는 결과를 적용할 수 있습니다. 이 말은 더 많은 오차 그레디언트가 모델에 흐른다는 의미고, 시간에 구애 받지 않습니다. 즉, 각 타임 스텝의 출력에서 그레디언트가 적용될 수 있습니다.
좀 더 풀어서 설명하면, 타임 스텝 0에서 타임 스텝 1 ~ 10까지 예측을 담은 벡터를 출력합니다. 그 다음 타임 스텝 1에서 2 ~ 11까지 예측을 담은 벡터를 출력합니다. 각 타겟 값은 입력 시퀀스와 길이가 동일합니다. 즉, 타겟 시퀀스틑 각 타임 스텝마다 10차원 벡터를 출력합니다.
위 방식을 적용할 수 있는 타겟 데이터를 새로 만들겠습니다.
# New 타겟 데이터
Y = np.empty((10000, n_steps, 10))
# Y.shape ==> (10000, 50, 10)
# 비어있는 Y에 값 채우기
for step in range(1, 10 +1):
Y[:,:,step-1] = series[:, step:step+n_steps, 0]
Y_trin = Y[:7000] # ==> (7000, 50, 10)
Y_valid = Y[7000:9000] # ==> (2000, 50, 10)
Y_test = Y[9000:] # ==> (1000, 50, 10)
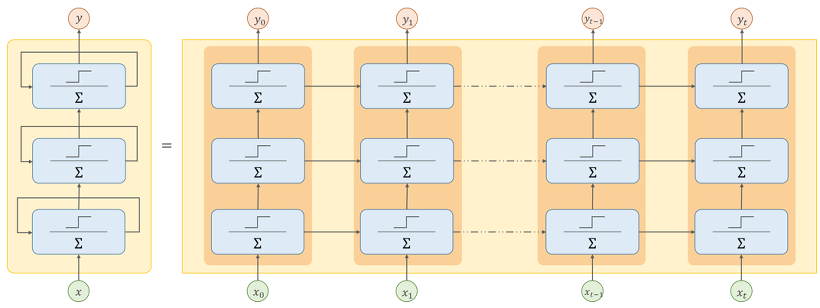
기본 RNN 모델을 시퀀스-투-시퀀스 모델로 바꾸려면 모든 순환 층의 결과 값을 출력하고 반영해야 합니다. 그래서 마지막 층에도 return_sequences=True 값을 부여해줍니다. 그런 다음 각 층에서 나온 출력값을 마지막 Dense Layer에 모두 적용해야 합니다. 이 부분을 가능하게 해주는 기능이 keras에서 TimeDistributed Layer를 제공합니다.
TimeDistributed Layer 작동 원리는 각 타임 스텝을 별개의 샘플처럼 다룰 수 있도록 입력 크기를 (배치 크기, 타임 스텝 수, 입력 차원) → (배치 크기 × 타임 스텝 수, 입력 차원) 으로 바꿉니다. 우리 코드에서는 SimpleRNN 유닛이 20개로 설정해서 입력 차원 수를 20으로 세팅한 후 Dense Layer에 적용됩니다. 그리고 Dense Layer에서 출력할 때는 다시 원래대로 (배치 크기, 타임 스텝 수, 입력 차원) 로 출력 크기가 변하고, Dense 유닛을 10이라고 지정해서 입력 차원을 10으로 세팅될 것입니다. 모델을 보겠습니다.
new_model = tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None,1]),
tf.keras.layers.SimpleRNN(20, return_sequences=True),
tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(10))
])
# 훈련 때는 모든 타임 스텝의 결과를 활용해서 MSE를 계산하는데
# 최종 실제 모델 평가 결과는 마지막 타임 스텝의 출력에 대한 MSE만 계산하면 되서 사용자 정의 지표를 만들 필요가 있다.
def last_time_step_mse(y_true, y_pred):
return tf.keras.metrics.mean_squared_error(y_true[:, -1], y_pred[:, -1])
new_model.compile(
optimizer = tf.keras.optimizers.Adam(lr=0.01),
loss = 'mse',
metrics = [last_time_step_mse]
)
new_history = new_model.fit(
train_x,
Y_trin,
epochs=20,
validation_data = (val_x, Y_valid)
)
# 최종 MSE 확인
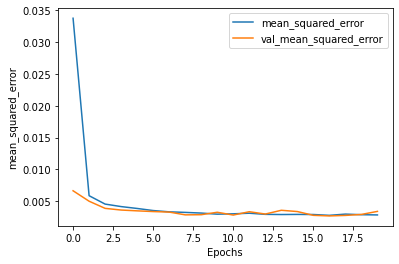
print(new_history.history['val_last_time_step_mse'][-1])
# ==> 0.006069639232009649
성능이 확실히 개선된 결과를 확인할 수 있습니다. 이 RNN 구조를 사용해서 다음 타임 스텝 10개를 예측하고 이 출력값을 다시 입력 시계열에 연결해서 다시 다음 10 타임 스텝의 값을 예측하도록 세팅할 수 있습니다.
지금까지 RNN 신경망에 대해 알아봤습니다. 한계점도 존재하는데 길이가 긴 시계열 데이터나 시퀀스 에서는 잘 작동하지 않습니다. 이 문제를 어떻게 해결할 수 있는지 다음 포스팅에서 다뤄보겠습니다.
NLP 자연어처리를 위한 RNN 알고리즘 코드 기초 (3) - 심층 RNN
NLP 자연어 처리를 위한 RNN 기초 (2) NLP 자연어 처리를 위한 딥러닝 RNN 기초 (1) RNN RNN은 Recurrent Neural Network 의 줄임말로 순환 신경망이라 불립니다. RNN 모델은 시퀀스 데이터를 효율적으로 처리하..
richdad-project.tistory.com
'AI > NLP' 카테고리의 다른 글
| [엘라스틱서치] 설치 및 세팅 (0) | 2023.01.07 |
|---|---|
| NLP 자연어 처리를 위한 딥러닝 - LSTM (5) (1) | 2021.12.18 |
| NLP 자연어처리를 위한 RNN 알고리즘 코드 기초 (3) - 심층 RNN (0) | 2021.12.16 |
| NLP 자연어 처리를 위한 RNN 기초 (2) (0) | 2021.12.15 |
| NLP 자연어 처리를 위한 딥러닝 RNN 기초 (1) (0) | 2021.12.14 |